概述
生成环境中,Ceph集群的部署是个非常专业的事情,需要懂Ceph的人来规划和部署,通常部署方式有两种:
1、ceph-deploy
2、ceph-ansible
无论上面的哪一种方式,都需要比较多的专业知识,这明显不适合规模化的需求或者测试环境的需求。而Rook则基于Kubernetes,有效的解决了Ceph集群的部署难题。
Rook
Rook简介
项目地址:https://github.com/rook/rook
Rook与Kubernetes结合的架构图如下:
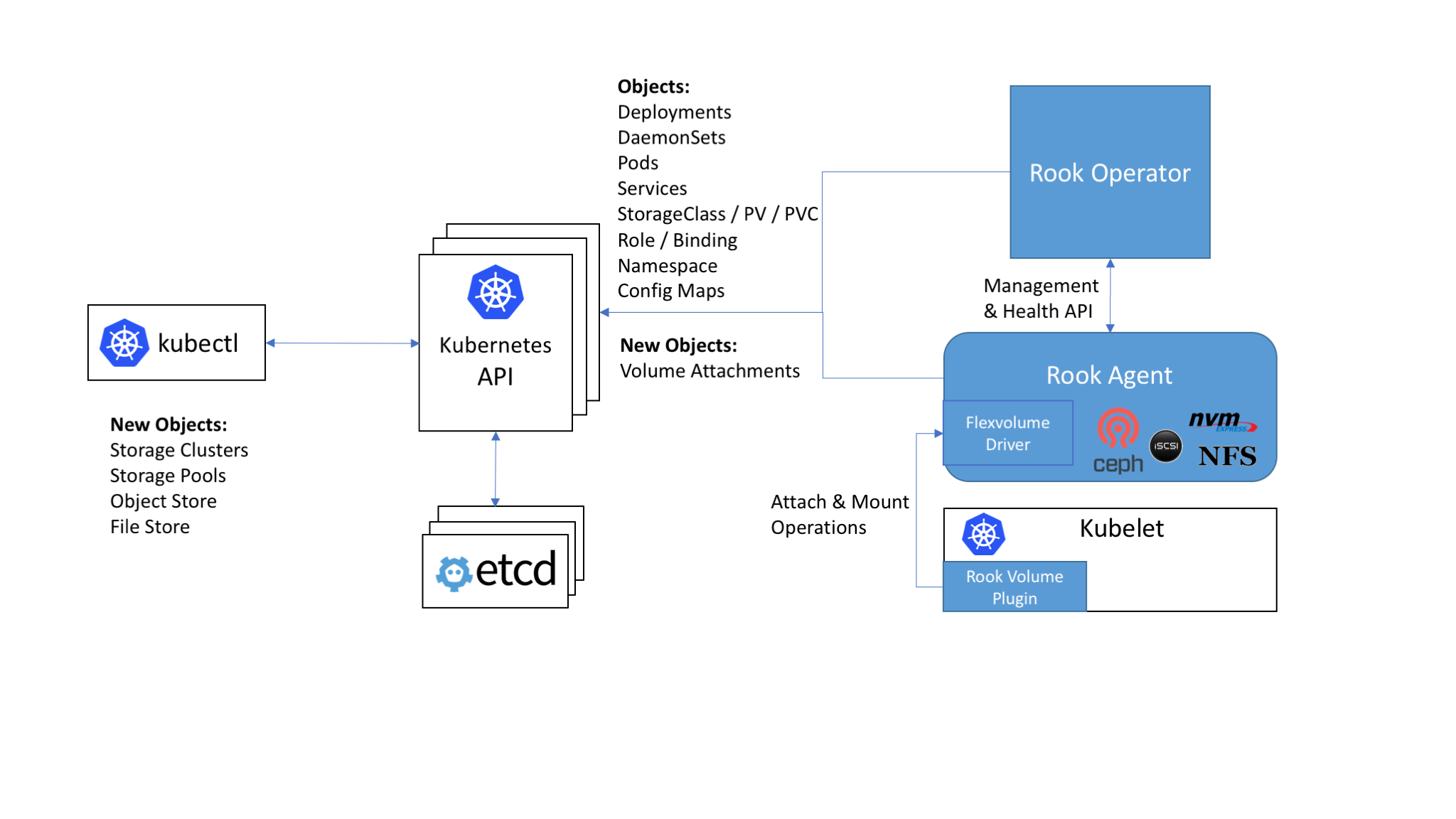
从上面可以看出,Rook是基于Kubernetes之上,提供一键部署存储系统的编排系统。
英文描述:Cloud-Native Storage Orchestrator
当前支持的存储系统有:
- Ceph
- NFS
- Minio
- CockroachDB
其中只有Ceph系统的支持处于beta版本,其他的都还是alpha版本,后续主要介绍通过Rook来部署Ceph集群。
Rook组件
Rook的主要组件有两个,功能如下:
Rook Operator
Rook与Kubernetes交互的组件
整个Rook集群只有一个
Rook Agent
- 与Rook Operator交互,执行命令
- 每个Kubernetes的Node上都会启动一个
- 不同的存储系统,启动的Agent是不同的
Rook & Ceph框架
使用Rook部署Ceph集群的架构图如下:
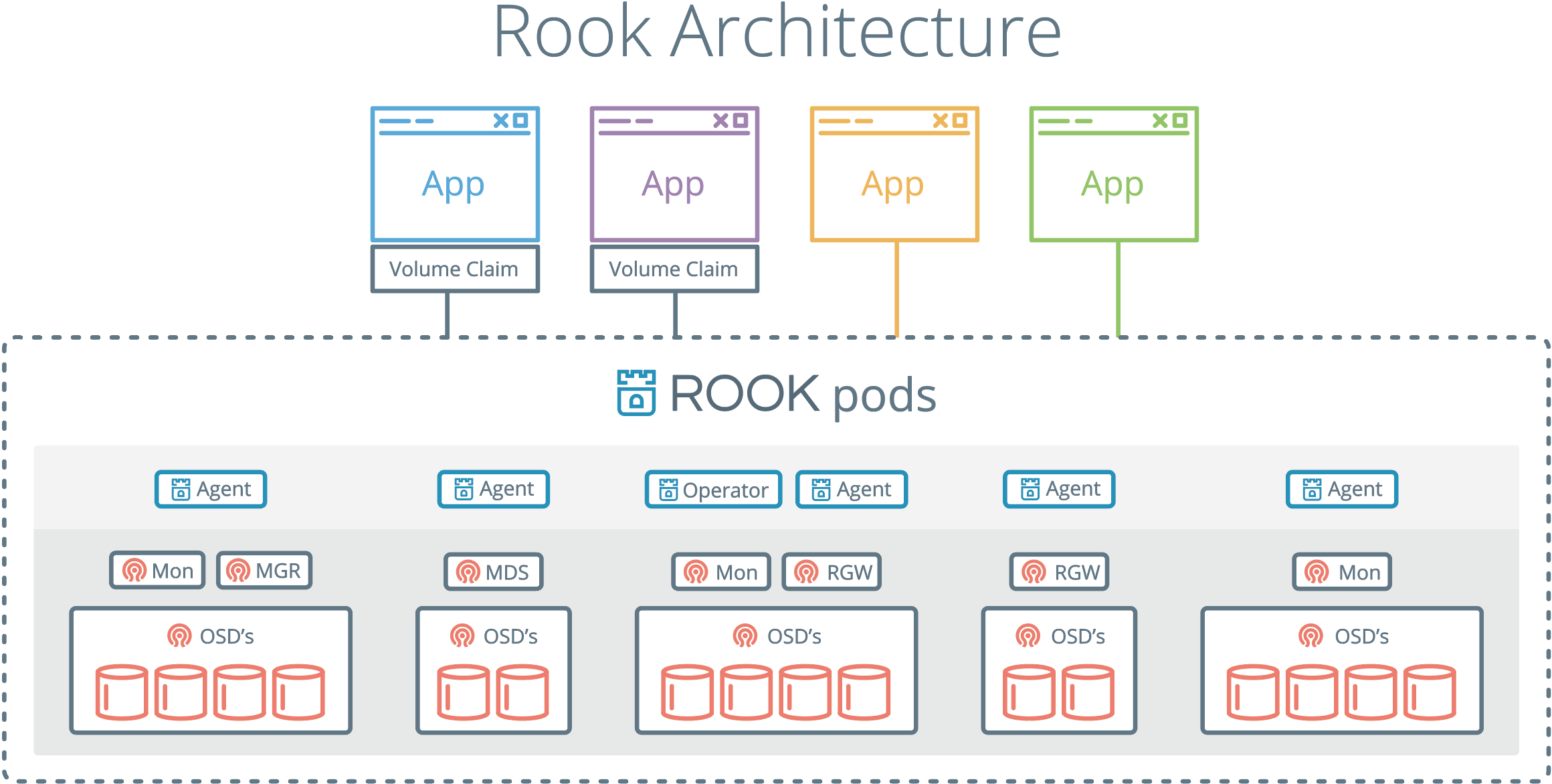
从上面可以看出,通过Rook部署完Ceph集群后,就可以提供Volume Claim给Kubernetes集群里的App使用了。
部署的Ceph系统可以提供下面三种Volume Claim服务:
- Volume:不需要额外组件;
- FileSystem:部署MDS;
- Object:部署RGW;
当前也就Ceph RBD支持的比较完善
部署Rook系统
Github上下载Rook最新release 0.9.0版本:https://github.com/rook/rook/tree/v0.9.0
要通过Rook部署Ceph集群,首先要部署Rook的两个组件:
1、Rook operator
2、Rook agent
如上面的Rook架构所示,Rook operator会启动一个pod,而Rook agent则会在kubernetes所有的nodes上都启动一个。
部署Rook的组件比较简单,如下命令:
1 | # cd rook-master/cluster/examples/kubernetes/ceph/ |
如上所示,它会创建如下资源:
- namespace:rook-ceph-system,之后的所有rook相关的pod都会创建在该namespace下面
- CRD:创建五个CRDs,
.ceph.rook.io - role & clusterrole:用户资源控制
- serviceaccount:ServiceAccount资源,给Rook创建的Pod使用
- deployment:rook-ceph-operator,部署rook ceph相关的组件
部署rook-ceph-operator过程中,会触发以DaemonSet的方式在集群部署Agent和Discoverpods。
所以部署成功后,可以看到如下pods:
1 | # kubectl -n rook-ceph-systemm get pods -o wide |
上述部署在第一次会比较慢,这是因为所有节点都要拉取rook/ceph:master镜像,有500多MB大小。
可以通过手动拉取一份,然后在各个节点上load的方式:
1 | # docker pull rook/ceph:master |
部署Ceph cluster
创建Ceph集群
当检查到Rook部署中的所有pods都为running状态后,就可以部署Ceph集群了,命令如下:
1 | # cd rook-master/cluster/examples/kubernetes/ceph/ |
如上所示,它会创建如下资源:
- namespace:roo-ceph,之后的所有Ceph集群相关的pod都会创建在该namespace下
- serviceaccount:ServiceAccount资源,给Ceph集群的Pod使用
- role & rolebinding:用户资源控制
- cluster:rook-ceph,创建的Ceph集群
Ceph集群部署成功后,可以查看到的pods如下:
1 | # kubectl -n rook-ceph get pods -o wide |
可以看出部署的Ceph集群有:
- Ceph Monitors:默认启动三个ceph-mon,可以在cluster.yaml里配置
- Ceph Mgr:默认启动一个,可以在cluster.yaml里配置
- Ceph OSDs:根据cluster.yaml里的配置启动,默认在所有的可用节点上启动
上述Ceph组件对应kubernetes的kind是deployment:
1 | # kubectl -n rook-ceph get deployment |
Ceph集群配置
monitor pod的ceph.conf:
1 | [root@rook-ceph-mon-a-6d9447cbd9-xgnjd ceph]# cat ceph.conf |
osd pod的ceph.conf:
1 | [root@rook-ceph-osd-2-67d5d8f754-qfxx6 ceph]# cat ceph.conf |
mgr pod的ceph.conf:
1 | [root@rook-ceph-mgr-a-959d64b9d-xld9r /]# cat /etc/ceph/ceph.conf |
Ceph集群的配置生成是代码中指定的,代码:pkg/daemon/ceph/config/config.go
[ceph默认配置]
1 | // CreateDefaultCephConfig creates a default ceph config file. |
删除Ceph集群
删除已创建的Ceph集群,可执行下面命令:
1 | # kubectl delete -f cluster.yaml |
删除Ceph集群后,在之前部署Ceph组件节点的/var/lib/rook/目录,会遗留下Ceph集群的配置信息。
若之后再部署新的Ceph集群,先把之前Ceph集群的这些信息删除,不然启动monitor会失败;
1 | # cat clean-rook-dir.sh |
部署Ceph集群的log
在部署Ceph集群中,可能出错或者不符合预期,这时候就需要查看对应的log,rook是通过rook-ceph-operator pod来执行部署Ceph集群的,可以查看它的log:
1 | # kubectl -n rook-ceph-system get pods -o wide | grep operrator |
Ceph组件的log
从上面章节中各个Ceph组件的ceph.conf文件中看出,配置的log输出为/dev/stderr,所以我们可以通过获取Ceph组件所在pod的log来查看Ceph组件的log:
1 | # kubectl -n rook-ceph log rook-ceph-mon-a-7c47978fbb-hbbjv |
Ceph toolbox部署
默认启动的Ceph集群,是开启Ceph认证的,这样你登陆Ceph组件所在的Pod里,是没法去获取集群状态,执行CLI命令的,这时需要部署Ceph toolbox,命令如下:
1 | # kubectl create -f toolbox.yaml |
部署成功后,pod如下:
1 | # kubectl -n rook-ceph get pods -o wide | grep ceph-tools |
然后可以登陆该pod后,执行Ceph CLI命令:
1 | # kubectl -n rook-ceph exec -it rook-ceph-tools-79954fdf9d-n9qn5 bash |
当不需要执行Ceph CLI命令时,可以通过kubectl命令很方便的删除:
1 | # kubectl create -f toolbox.yaml |
RBD服务
在kubernetes集群里,要提供rbd块设备服务,需要有如下步骤:
- 创建rbd-provisioner pod
- 创建rbd对应的storageclass
- 创建pvc使用rbd对应的storageclass
- 创建pod使用rbd pvc
通过rook创建Ceph Cluster之后,rook自身提供了rbd-provisioner服务,所以我们不需要再部署其provisioner。
代码:pkg/operator/ceph/provisioner/provisioner.go
创建pool和StorageClass
1 | # cat storageclass.yaml |
创建pvc
创建一个pvc,使用刚才配置的rbd storageclass。
1 | # vim tst-pvc.yaml |
在Ceph集群端检查:
1 |
|
创建pod
创建一个pod,配置使用刚才创建的rbd pvc。
1 | # vim tst-pvc-pod.yaml |
登陆pod检查rbd设备:
1 | # kubectl get pods -o wide |
CephFS服务
与RBD服务类似,要想在kubernetes里使用CephFS,也需要一个cephfs-provisioner服务,在Rook代码里默认还不支持这个,所以需要单独部署。
参考:https://github.com/kubernetes-incubator/external-storage/tree/master/ceph/cephfs
创建CephFS
可以通过下面的命令快速创建一个CephFS,根据自己的需要配置filesystem.yaml:
1 | # cat filesystem.yaml |
执行命令:
1 | # kubectl create -f filesystem.yaml |
我们配置 activeCount : 2,activeStandby: true,所以这里创建了4个MDS Daemons
mds pod的ceph.conf:
1 | [root@rook-ceph-mds-cephfs-a-57db46bfc4-2j9tq /]# cat /etc/ceph/ceph.conf |
检查CephFS状态:
1 | [root@ke-dev1-worker1 /]# ceph fs ls |
创建StorageClass
获取Ceph client.admin的keyring:
1 | # ceph auth get-key client.admin |
创建kubernetes的secret:
1 | # cat secret |
基于上面创建的adminsecret,创建对应的Storageclass;
1 | # cat storageclass.yaml |
创建pvc
测试pvc的yaml如下:
1 | # cat tst-pvc.yaml |
创建测试的pvc,并检查其状态:
1 | # kubectl create -f tst-pvc.yaml |
创建pod
创建测试pod的yaml如下:
1 | # cat tst-pvc-pod.yaml |
创建测试pod挂载使用上一步创建的pvc:
1 | # kubectl create -f tst-pvc-pod.yaml |
在ceph tool的pod里安装ceph-fuse,然后mount cephfs后检查:
1 | [root@ke-dev1-worker1 ~]# yum install -y ceph-fuse |
总结
本文主要介绍了如何通过Rook在Kubernetes上部署Ceph集群,然后如何来提供Kubernetes里的PV服务:包括RBD和CephFS两种。
整个操作过程还是比较顺利的,对于熟悉Kubernetes的同学来说,你完全不需要理解Ceph系统,不需要理解Ceph的部署步骤,就可以很方便的来通过Ceph系统提供Kubernetes的PV存储服务。
但真正遇到问题的时候,还是需要Rook系统的log 和 Ceph Pod的log来一起定位,这对于后期维护Ceph集群的同学来说,你需要额外的Kubernetes知识,熟悉Kubernetes的基本概念和操作才行。

