概述
Ceph从Luminous开始,默认使用了全新的存储引擎BlueStore,来替代之前提供存储服务的FileStore,与FileStore不一样的是,BlueStore直接管理裸盘,分配数据块来存储RADOS里的objects。
Bluestore比较复杂,学习BlueStore的关键就是查看其实现的 ”object → block device“ 映射,所以本文先重点分析下该部分:一个Object写到Bluestore的处理过程。
Bluestore整体架构
下面借用Sage Weil的图描述下BlueStore的整体架构:
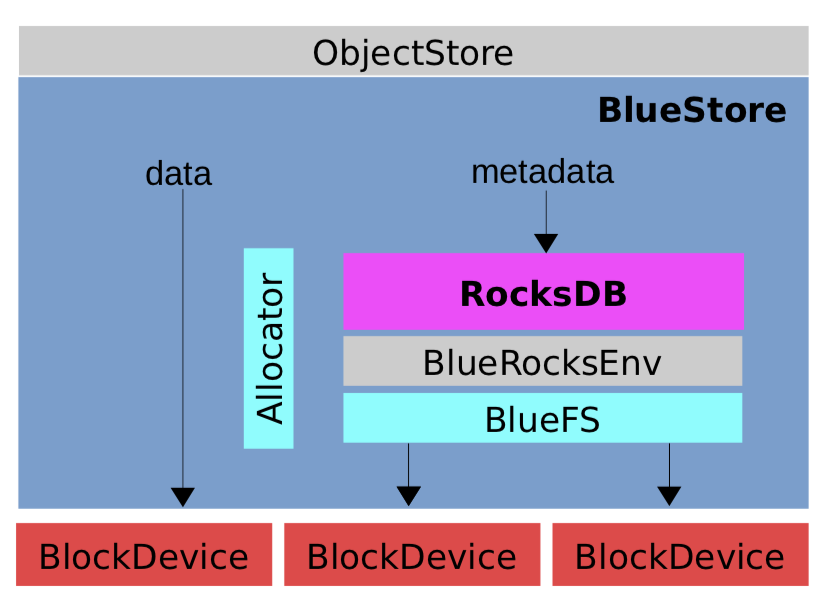
里面的几个关键组件介绍:
- RocksDB:存储元数据信息
- BlueRocksEnv:提供RocksDB的访问接口
- BlueFS:实现BlueRocksEnv里的访问接口
- Allocator:磁盘分配器
针对BlueStore的整体架构不做展开,大家只需对其几大组件有些了解即可,本文继续介绍Object写操作到底层BlockDevice的过程。
BlueStore中Object到底层Device的映射关系
这里先从整体上给出在BlueStore中,一个Object的数据映射到底层BlockDevice的实现,如下图:
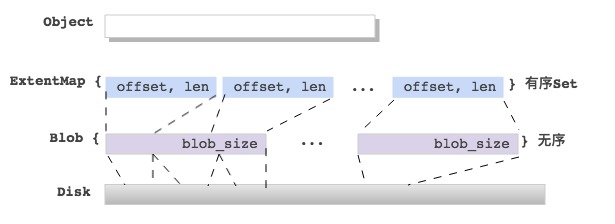
首先详细介绍下与上诉映射关系相关的数据结构。
Bluestore相关数据结构
BlueStore里与Object 数据映射相关的数据结构罗列如下:
Onode
任何RADOS里的一个Object都对应Bluestore里的一个Onode(内存结构),定义如下:
1 | struct Onode { |
通过Onode里的ExtentMap来查询Object数据到底层的映射。
ExtentMap
ExtentMap是Extent的set集合,是有序的,定义如下:
1 | struct ExtentMap { |
ExtentMap还提供了分片功能,防止在文件碎片化严重,ExtentMap很大时,影响写RocksDB的性能。
ExtentMap会随着写入数据的变化而变化;
ExtentMap的连续小段会合并为大;
覆盖写也会导致ExtentMap分配新的Blob;
Extent
Extent是实现object的数据映射的关键数据结构,定义如下:
1 | struct Extent : public ExtentBase { |
每个Extent都会映射到下一层的Blob上,Extent会依据 block_size 对齐,没写的地方填充全零。
Extent中的length值,最小:block_size,最大:max_blob_size
Blob
Blob是Bluestore里引入的处理块设备数据映射的中间层,定义如下:
1 | struct Blob { |
每个Blob会对应一组 PExtentVector,它就是 bluestore_pextent_t 的一个数组,指向从Disk中分配的物理空间。
Blob里可能对应一个磁盘pextent,也可能对应多个pextent;
Blob里的pextent个数最多为:max_blob_size / min_alloc_size;
Blob里的多个pextent映射的Blob offset可能不连续,中间有空洞;
AllocExtent
AllocExtent是管理物理磁盘上的数据段的,定义如下:
1 | struct bluestore_pextent_t : public AllocExtent { |
AllocExtent的 length值,最小:min_alloc_size,最大:max_blob_size
BlueStore写数据流程
BlueStore里的写数据入口是BlueStore::_do_write(),它会根据 min_alloc_size 来切分 [offset, length] 的写,然后分别依据 small write 和 big write 来处理,如下:
1 | // 按照min_alloc_size大小切分,把写数据映射到不同的块上 |
BlueStore Log分析
可以通过开启Ceph bluestore debug来抓取其写过程中对数据的映射,具体步骤如下。
下面通过在CephFS上测试为例:
1 | 1. 创建一个文件 |
通过上述方式可以搜集到Bluestore在写入数据时,object的数据分配和映射过程,可以帮助理解其实现。
BlueStore dd write各种case
为了更好的理解BlueStore里一个write的过程,我们通过dd命令写一个Object,然后抓取log后分析不同情况下的Object数据块映射情况,最后结果如下图所示:
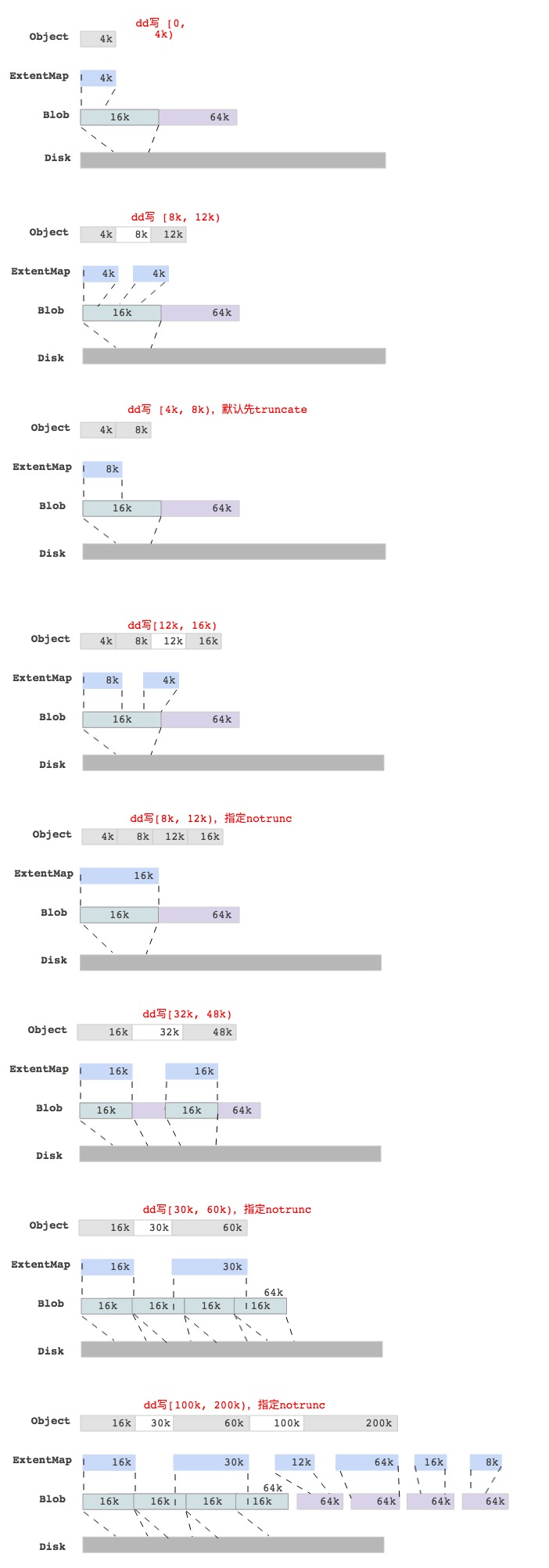
注释:上图的数据块映射关系是通过抓取log后获取的。
最后一图中,写[100k, 200)的区域,查看Object对应的ExtentMap并不是与 min_alloc_size(16k)对齐的,只是保证是block_size(4k)对齐而已。

